
티스토리 뷰
Consumer
consumer들은 각각 고유의 속도로 commit log로부터 순서대로 poll하게 된다.
다른 consumer group에 속한 consumer들은 서로 관련이 없고 또한, 한 partition의 commit log에 있는 record를 동시에 다른 위치에서 read가 가능하다.
consumer offset
consumer가 자동, 수동으로 읽은 데이터의 위치를 commit하여 다시 읽음을 방지한다.
__consumer_offsets라는 internal topic(기본적으로 kafka를 설치하면 있는 topic)에서 consumer offset을 저장하여 관리한다.
format 예시) GroupB:MyTopic:P0:8
partition이 2개 이상인 경우에는 모든 메시지에 대한 전체 순서 보장은 불가능하다.
왜냐하면, 위에서 말했듯 "consumer들은 각각 고유의 속도로 commit log로부터 순서대로 poll하게 된다." 라는 말로 유추해볼 수 있다.
- partition별로 각각 consumer가 동작하기 때문이다.
- partition은 하나로 하면 순서가 보장되지만 kafka라는 분산형 messageQ를 쓰는 이유가 없어진다.(병렬처리가 안되기 때문에)
- 동일한 key를 가진 메시지는 동일한 partition에만 전달되어 key 레벨의 순서 보장이 가능하다.
- 운영중 partition 개수 변경시 순서 보장이 불가능하다. 이러한 이유로 운영중인 topic에 partition의 갯수를 변경하지 않는게 좋다.
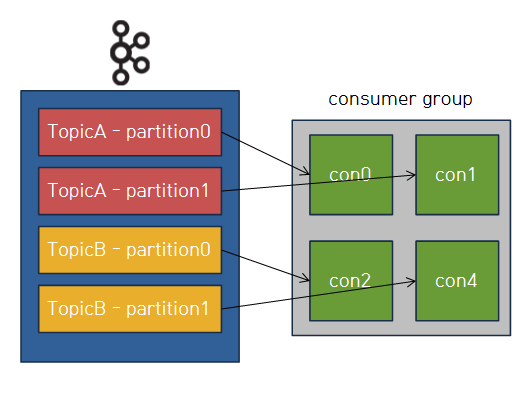
Consumer Group
consumer는 consumer group을 두면서 kafka에 있는 record를 병렬적으로 처리할 수 있게 한다.
예를 들어 4개의 partition이 있는 topic을 consume하는 4개의 consumer가 하나의 group에 있다면,
각각의 consumer는 정확히 하나의 partition에서 record를 consume하게 된다.

같은 group내의 consumer는 각각의 partition을 분배받게 된다.
왜냐하면 partition은 항상 consumer group내에서 하나의 consumer에 의해서만 사용된다.
consumer는 주이진 topic에서 0개 이상의 많은 partition을 사용 가능하다.
하지만 동일한 topic에서 consume하는 여러 consumer group이 있을 수 있다.
이러한 경우는 보통 같은 record(데이터)를 다른 목적으로 사용할 경우라고 할 수 있다.
Consumer Read Position
- Last Commited Offset(Current Offset): consumer가 최종 commit한 offset
- Current Posision: consumer가 읽어간 위치(현재 처리중인 것. commit 전)
- High Water Mark(복제 완료 된): ISR(Leader-Follower)간에 복제된 Offset
- Log End Offset: Producer가 메시지를 보내서 저장된 로그의 맨 끝 Offset
- Consumer lag = (Log End Offset) - (Last Commited Offset)
Consumer의 순서 보장
전체 데이터에 대한 순서는 partition이 2개 이상인 경우 불가능하다.
하지만, key를 이용해 들어갈 partiton을 정하기 때문에 key 값을 통한 partition내의 순서 보장은 가능하다.
Consumeing Proces
Consumer가 partition을 배정받는 과정은 Group Coordinator(broker중 하나)와 group leader(consumer중 하나)의 상호작용으로 이루어진다.
Rebalance
consumer에서 record를 읽는게 fail하게 되면 rebalancing을 통해서 재배치 된다.
다른 consumer(같은 group내)가 fail 된 consumer의 partition하나를 가져가게 된다.
processing sequence
- Consumer를 등록하고 group coordinator를 선택하게 된다.
- Consumer에 group.id를 등록하게 되면, kafka가 자체적으로 group을 만들게 된다.
- __consumer_offsets이라는 internal topic에 하나의 partition에 저장된다.
- 위 partition의 leader broker는 consumer group의 Group Coordinator로 선택하게 된다.
- partitioner의 [hash(group.id)%offsets.topic.num.partitions]통해서 group.id가 저장될 __consumer_offsets의 partition을 정한다.
- JoinGroup 요청 순서에 따라 consumer를 나열한다.
- Group Coordinator는 JoinGroup이라는 request를 날린다.
- group.initial.rebalance.delay.ms 의 옵션값을 통해 그 시간동안 왔던 consumer를 해당 group에 join 시킨다.
- Group Leader 결정: partitoin 할당 최초 요청을 보낸 consumer가 group leader가 된다.
- Group Leader에서 각 partition들의 맵핑을 하고 그에 대한 정보를 Group Coordinator에 보낸다.
- 각 Consumer에 할당된 partition 정보를 보낸다.
Kafka는 최대한 broker의 부담을 줄여주려고 노력한다.
그래서 가능한의 많은 계산을 클라이언트(consumer)가 수행하도록 한다.
위의 process에서도 맵핑을 하는 과정을 Group Leader에게 맡기는 것과 rebalancing 또한 consumer가 연산을 한다.
이러한 이유로 consumer rebalancing시에 consumer들은 메시지를 consume하지 못한다.
따라서 불필요한 rebalancing을 피해야한다.
Consumer heartbeat 설정
heartbeat.interval.ms=3
# consumer는 poll()과 별도로 백그라운드 Thread에서 Heartbeats를 보낸다.
session.timeout.ms=10
# 위 변수의 시간동안 heartbeat가 수신되지 않으면 Consumer는 Consumer group에서 삭제된다.
max.poll.interval.ms=5
# poll()은 heartbeats와 상관없이 주기적 호출된다.
과도한 Rebalancing을 피하는 방법
- Consumer group 멤버 고정
- 고유한 group.instance.id를 할당
- LeaveGroupRequest 미사용
- session.timeout.ms 튜닝
- heartbeat.interval.ms를 session.timeout.ms의 1/3으로 설정
- group.min.session.timeout.ms, group.max.session.timeout.ms의 사이값
- 늘릴때의 장점: rejoin할 수 있는 시잔을 제공, 단점: consumer장애 감지 오래걸림
- max.poll.interval.ms 튜닝
- Consumer에게 poll()한 데이터를 처리할 충분한 시간 제공
Partition Assignment Strategy(파티션 할당 전략)
consumer에게 partition을 할당하는 전략은 partition.assignment.strategy로 할당 방식을 조절 할 수 있다.
- RangeAssignor: Topic 별로 작동하는 Default Assignor
- paritition의 번호과 consumer group의 consumer 번호와 동일하게 할당하는 방식이다.
- partition의 갯수가 consumer group의 consumer의 갯수보다 적다면 계속 노는 consumer가 생긴다.

- RoudRobinAssignor: RoundRobin 방식으로 Consumer에게 partition 할당
- StickyAssignor: 최대한 많은 기존 partition할당을 유지하며 최대 균형
- RoudRobin과 동일하지만 재할당(rebalancing)하는 방식에서 기존 연결을 유지하고 재할당 한다.
- 재할당 전략으로는 consumerA가 다른 consumerB들에 비해 2개 이상 적은 topic partition이 할당된 경우, A에 할당된 topic의 나머지 partition들은 B에 할당될 수 없다.
- CooperativeStickyAssignor:RangeAssignor와 비슷하지만 협력적 rebalancing 허용
- 기존에 사용되던 Rebalancing은 Eager Rebalancing 프로토콜(consumer가 추가되면 단순히 partition의 재배정이 일어난다.)
- 재배정 동안에는 consumer들의 consume 동작이 모두 멈추게 된다는 점에서 느려진다.
- 해당 방식은 새로운 consumer가 추가될때 배정될 partition만 revoke(중단) 시킨다는 개념이다.
- 간단하게, rebalancing을 2번해 처음에는 배정만 하고 변화를 시키지 않고, 두번째에는 변화가 있는 partition만 배정을 하는 것이다.
- ConsumerPartitionAssignor: 인터페이스를 구현하면 사용자 지적 할당 전략 사용 가능
Consumer 관련 CLI
Consumer 관련 CLI는 kafka-console-consumer.sh 쉘 파일을 이용한다.
# message consume
$ kafka-console-consumer.sh --bootstrap-server my-kafka1:9092,my-kafka2:9092,my-kafka3:9092 \
--topic hello.kafka \
--property parse.key=true \
--property key.separator="-" \
--group hello-group \
--from-beginning
# consumer group 조회
$ kafka-consumer-groups.sh --list \
--bootstrap-server my-kafka1:9092,my-kafka2:9092,my-kafka3:9092
# consumer group 상세 조회
$ kafka-consumer-groups.sh --describe \
--bootstrap-server my-kafka1:9092,my-kafka2:9092,my-kafka3:9092 \
--group hello-group'Infra > Kafka' 카테고리의 다른 글
| 5_Replication (0) | 2022.08.16 |
|---|---|
| 3_Producer (0) | 2022.08.11 |
| 2. Kafka - Broker, Zookeeper (0) | 2022.07.04 |
| 1. Kafka - Topic (0) | 2022.07.04 |
| 0. Apache Kafka (0) | 2022.07.04 |
- Total
- Today
- Yesterday
- JPA
- apache
- rhel
- consumer
- React
- K8S
- Producer
- frontend
- feign client
- 프론트엔드
- API
- KAFKA
- broker
- spring boot
- spring
- caching
- apache kafka
- Java
- NextJS
- zookeeper
- backend
- 리액트
- Linux
- Front
- centos
- Container
- cs
- OS
- Data Engineering
- Firebase
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |